Continuing on the series of games that DQN and its descendants learn to play well: crazy climber. In this game, you climb a building by moving the joystick up, which lifts your arms, and pulling it back down, which lifts you up. You are grabbing onto the ledge of windows which are open. The windows occasionally close, and if you are holding from their ledge at the time, you fall.
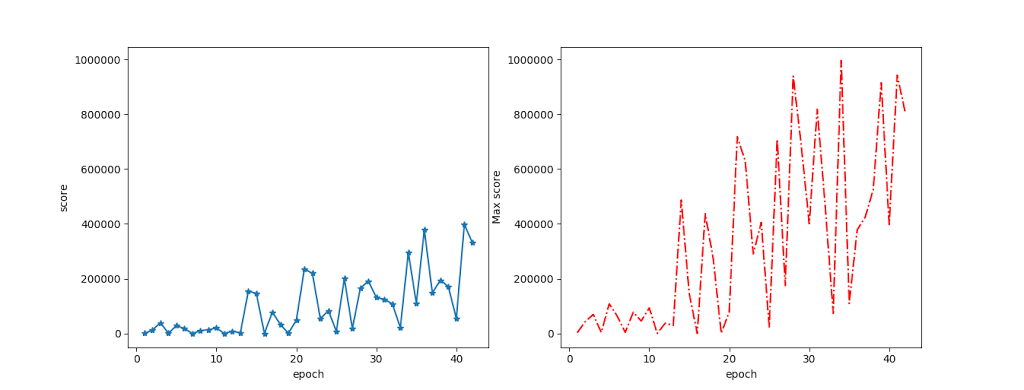
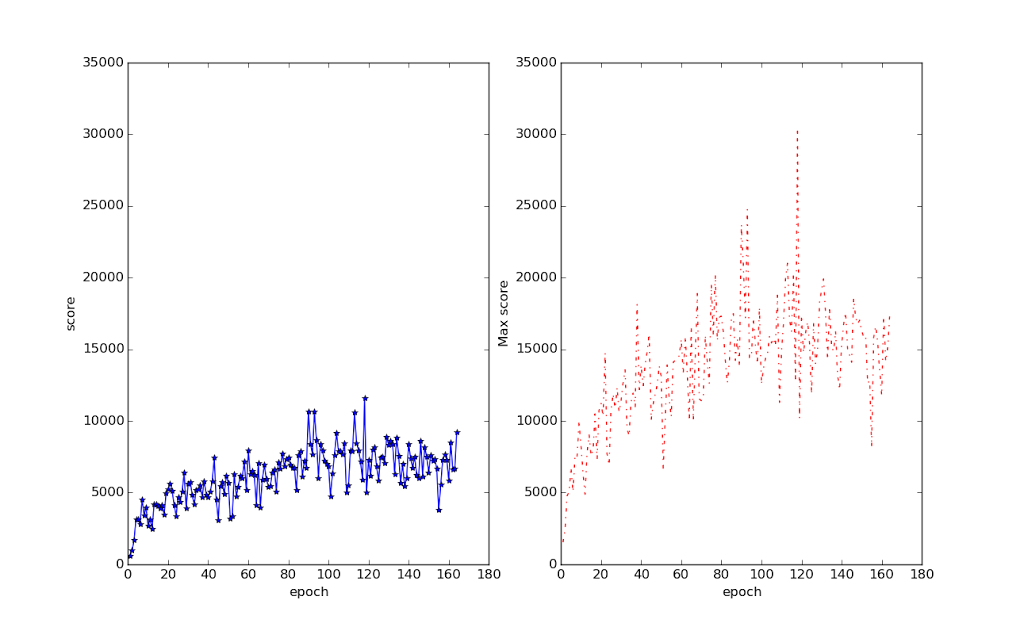
DQN learns to play this game reasonably well in no time at all. This, I think, is because it receives rewards for every step up it climbs. This extremely dense reward suits Q-learning perfectly, and it just learns to climb extremely fast.
The problem is that it seems to get addicted to just climbing fast, and it ignores almost all of the rest of the game. It is so fast that windows very rarely close on it, so in situations where a human would stop and wait, it just runs through them and gets away with it most of the time.
Already by the end of the first epoch it knows to just leg it up quickly, but it doesn’t know to move sideways once it hits the end of a column onto one with more floors to climb, only drifting sideways by random movements, like this:
Learning to move quickly to the open column takes it a couple more epochs.
It later seems to learn to hold on to the ledge with both hands when it’s going to get hit by something, like an egg dropped by a bird. If you are not holding on, you fall. It also learns to catch onto the helicopters at the end of each level for bonus points.
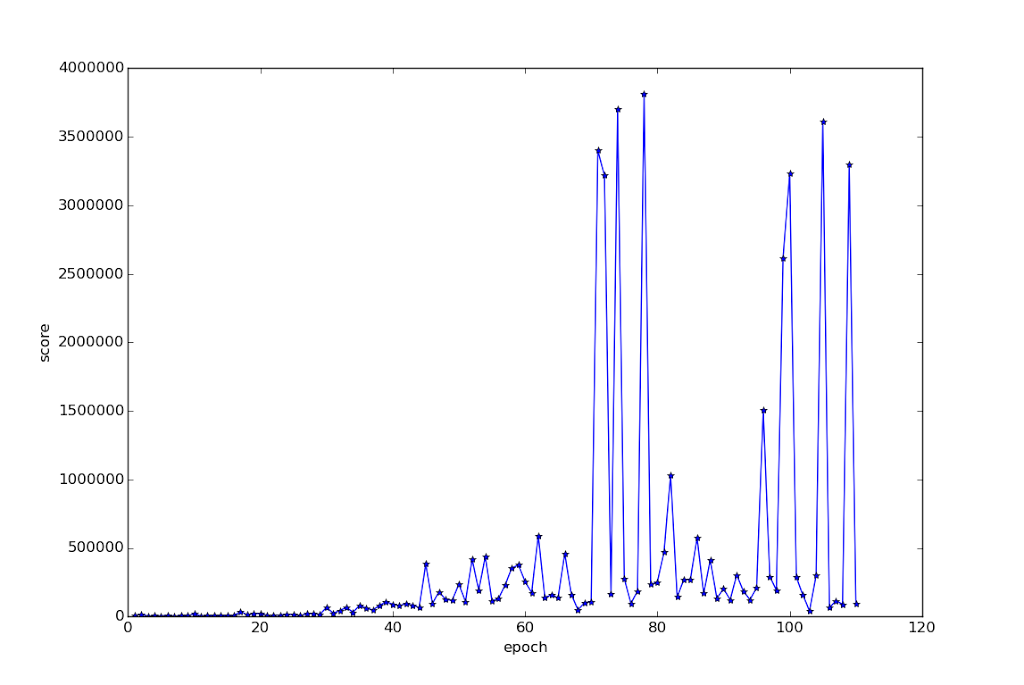
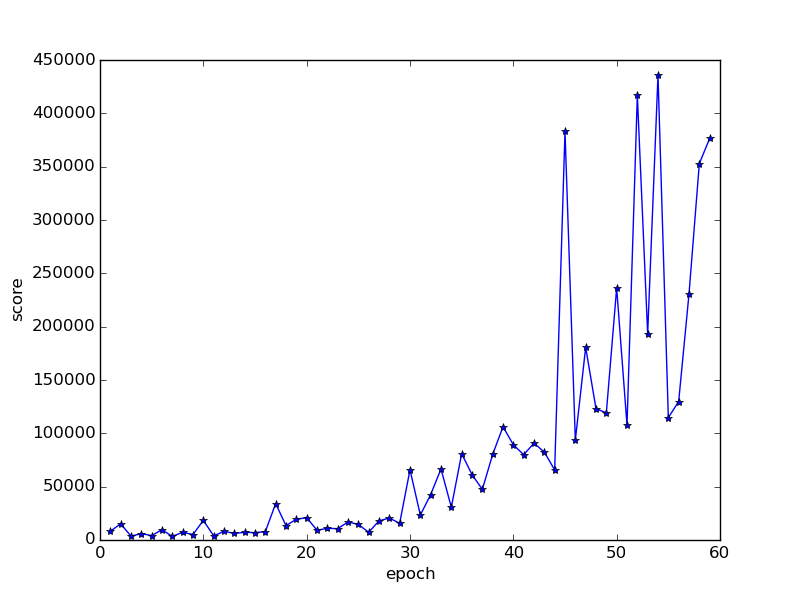
What it never really seems to learn is to wait for the windows to reopen, or to move sideways onto a clearer path. This still lets it get to about 100,000 points on average due to the huge bonuses it gets for completing the levels quickly. This is higher than DeepMind’s testers which is about 35,000 points. The world record is a surprisingly-low-to-me 219,000 which is probably due to the cartridge having been hard to find in its console days. (While I was writing this post, the APE-X paper was published claiming a score of around 320,000 in Crazy climber. This would beat both the human record, and it probably means it learnt other tricks)
The usual learning progress video:
You can download a trained version of the network from https://organicrobot.com/deepqrl/crazy_climber_20151018_e90_54374b2c86698bd8c71ca8d5936404340c0bea2d.pkl.gz . It was trained by running run_nature.py.
To use the trained network, you’ll need to get some old versions of the respective code repositories because this was trained back in October 2015 Late November 2015 versions of Nathan Sprague’s deep Q learning code https://github.com/spragunr/deep_q_rl, or commit f8f2d600b45abefc097f6a0e2764edadb24aca53 on my branch https://github.com/alito/deep_q_rl, Theano https://github.com/Theano/Theano commit 9a811974b934243ed2ef5f9b465cde29a7d9a7c5, Lasagne https://github.com/benanne/Lasagne.git commit b1bcd00fdf62f62aa44859ffdbd72c6c8848475c and cuDNN 5.1 work.