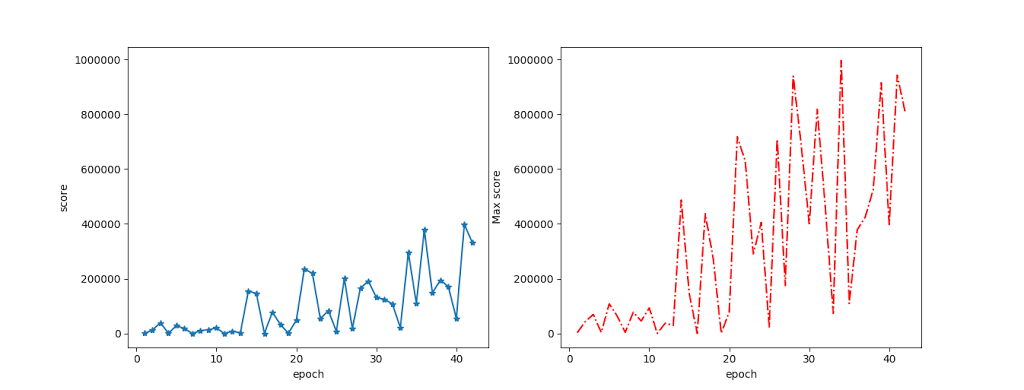
Like Atlantis, Video pinball is another game where DQN and its derivatives do very well compared to humans, scoring 10s of times higher than us. I looked at the game and trained an agent using Nathan Sprague’s code, which you can get from https://github.com/spragunr/deep_q_rl, to see what was happening.
In summary: patience was what was happening. The secret to the game, or at least how DQN manages to score highly, is by very frequent and well timed bumping, putting and keeping the ball in a vertical bounce pattern across one of the two point-gathering zone that you can see surrounded by the vertical bars at the left and right near the top of the screen, like this:
It’s not easy to tell but there’s a lot of nudging of the ball going on while it’s in flight.
Here’s the usual learning graph:
On the left is the average score per epoch, on the right the maximum score per epoch. For reference, in the DeepMind papers, they tend to list human scores of around 20,000. As noted at the bottom top human scores are actually far above this.
The progress video is not very interesting. The untrained network doesn’t know how to launch the ball, so there’s nothing to see. It then learns to launch the ball and perform almost constant but undirected bumps, which get it to around 20,000 points (around “human level”), before discovering its trick, after which the scores take off. There’s probably more noticeable progress along the line related to recovery techniques in the cases where the ball escapes, but it doesn’t feel worth trawling through hours of video to discover them.
In summary, like in the case of Atlantis, I think this game is “solved”, and it shouldn’t be used for algorithm comparison in a quantitative way. It could just be a binary “does it discover the vertical trapping technique?” like Atlantis is about “does it discover that shooting those low fast-flying planes is all important?” and that’s all. The differences in score are probably more to do with the random seed used during the test run.
Unlike in Atlantis, these scores aren’t actually superhuman. TwinGalaxies reports a top score of around 38 million. You can watch this run in its full 5-hour glory here: http://www.twingalaxies.com/showthread.php/173072. This is still far, far above whatever DQN gets.
I’ve uploaded the best-performing network to http://organicrobot.com/deepqrl/video_pinball_20170129_e41_doubleq_dc48a1bab611c32fa7c78f098554f3b83fb5bb86.pkl.gz. You’ll need to get Theano from around January 2017 to run it (say commit 51ac3abd047e5ee4630fa6749f499064266ee164) since I trained this back then and they’ve changed their format since then. I think I used the double Q algorithm, but it doesn’t make much difference whether you use that or the standard DQN I imagine.
I think DeepMind was a bit unlucky in not choosing Galaxian as one of their original set of games to train on. It’s a very popular game, much more interesting than its Space Invaders ancestor, and, more importantly, their algorithm learns great on it.
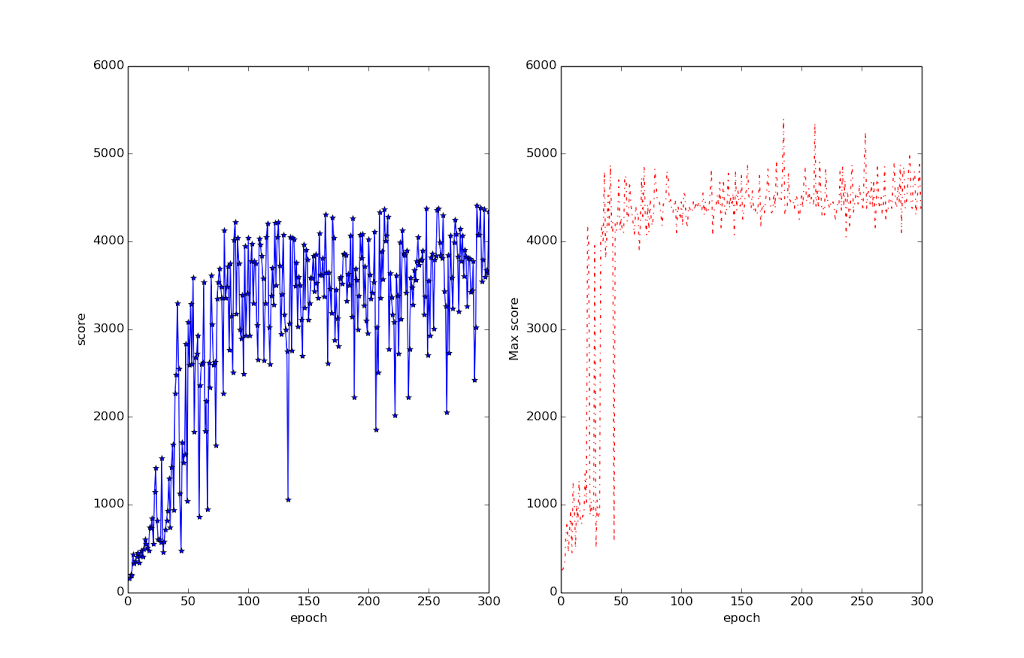
Here are the usual graphs for it:
Note that, unlike in the Space Invaders case, these scores are very much human-level. Those scores in the high 20,000 range are really hard to get unless you play the game a lot. Even the 10,000 average is very respectable. It also very quickly reaches perfectly-reasonable and quite human-styled levels of play (less than 10 epochs).
While DeepMind’s papers show their algorithm doing better than some random person on a game they don’t play much while having to use a keyboard when playing for five minutes (“expert human player” scoring 31 on breakout, c’mon), they don’t try to show their programs getting better scores than human experts at their own games. I am not really sure why they chose their 5-minute limit for reporting, but the rest of us don’t have to abide by it, and in here we can show that if you remove the 5-minute limit, the algorithm can beat the best human scores in at least one game.
One of the games that stands near the top of the DeepQ / human ratio in their papers is Atlantis. It’s a game where planes fly overhead and you shoot them down from one of three guns. Most planes that fly past are harmless and are only there to score points from. Every now and then a plane firing a laser down comes across and if you fail to shoot it down it will destroy one of your guns or one of your other “buildings”. When all of your buildings are destroyed, the game is over. One unusual feature of the game is that your buildings and guns reappear if you score enough points.
It would be very easy to write a program to play this game almost perfectly if you could hand-code it. The sprites are pretty much always the same, the planes always appear at the same height and the game never changes. You could write an if-detect-plane-here-then-shoot program and it would do amazingly well. It’s a lot harder if you are not hand-coding almost anything like DeepQ does.
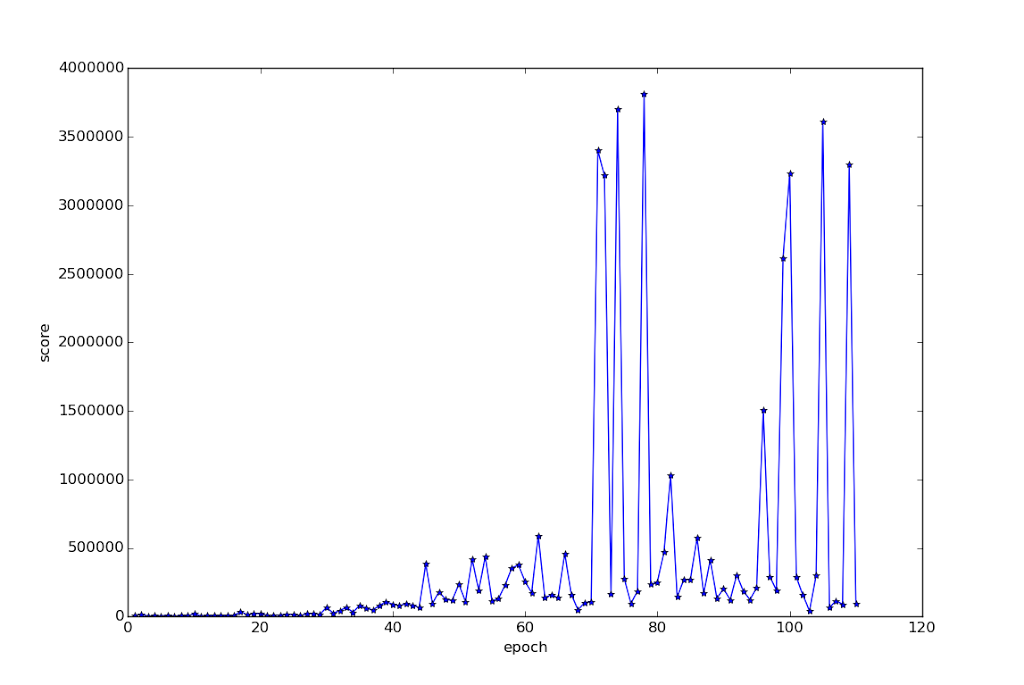
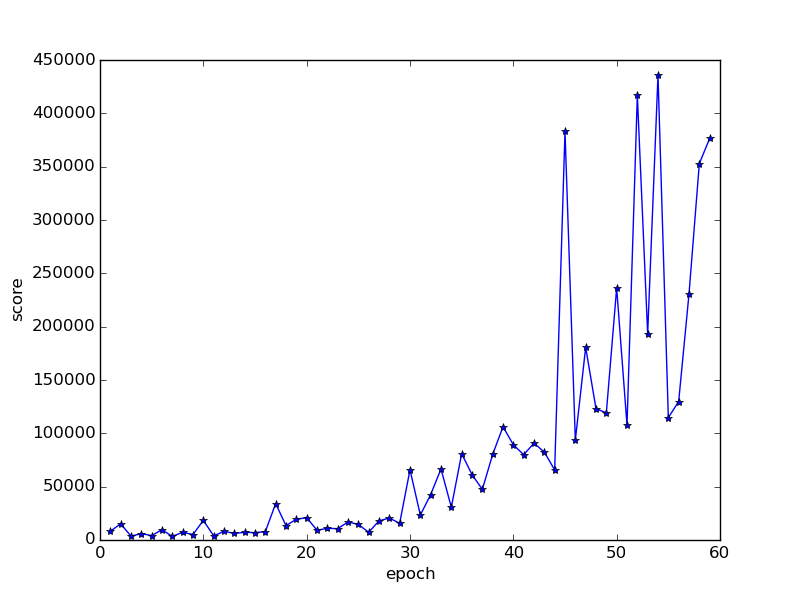
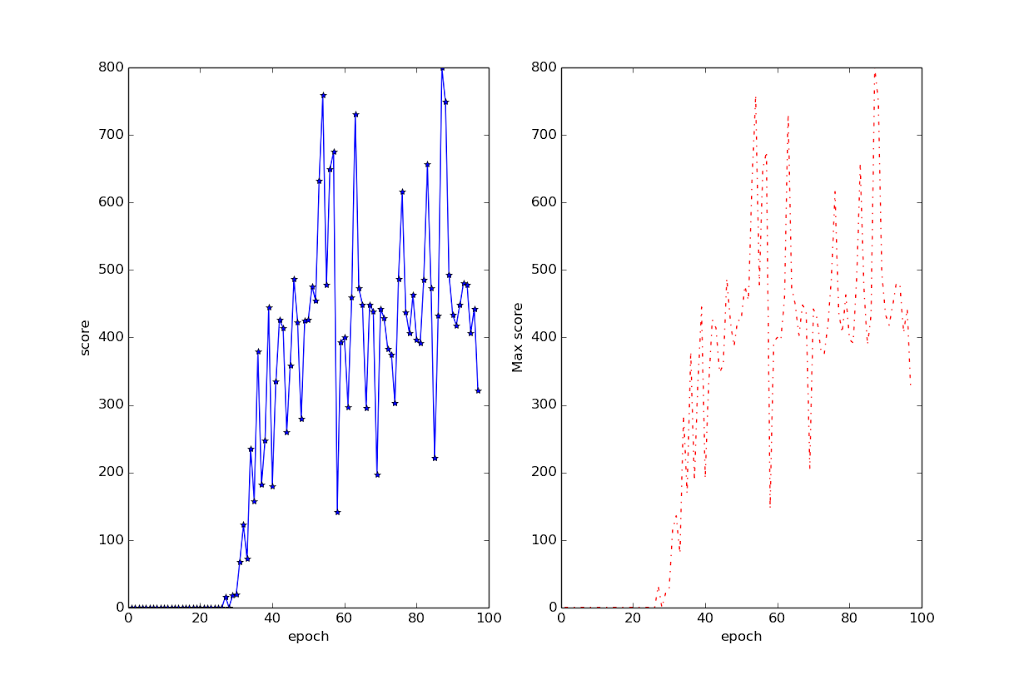
DeepQ learns to play this game relatively quickly. There is constant feedback from shooting down planes, and because of the loss-of-life marker, the program gets instant feedback when one of its buildings or guns is destroyed. Here’s the training graph for it.
And here’s the first 60 epochs or so since the latter epochs are hiding the early landscape:
As you can see, the learning is quite gradual until the huge spikes. There is even quite a bit of improvement before epoch 30 that is being hidden in the zoomed in image, although given the constant feedback I’d have expected it to have improved even faster. The scores are very high from epoch 40 onwards. For reference the score quoted on DeepMind’s Nature paper ( http://www.nature.com/nature/journal/v518/n7540/full/nature14236.html ) are around 30000 for humans and 85000 for DQN.
The spikes on the first graph are huge, but they turn out to be artificially LOW because of the limit of playing time imposed on the testing period during training (125,000 actions, which is roughly two hours 20 minutes of play). I grabbed the model that produced the highest one, on epoch 78, and set it to play with unlimited time. After over 20 hours of gameplay, with the emulator running very slowly (bug yet to be investigated), and me doubting it was ever going to finish the game, I killed the run.
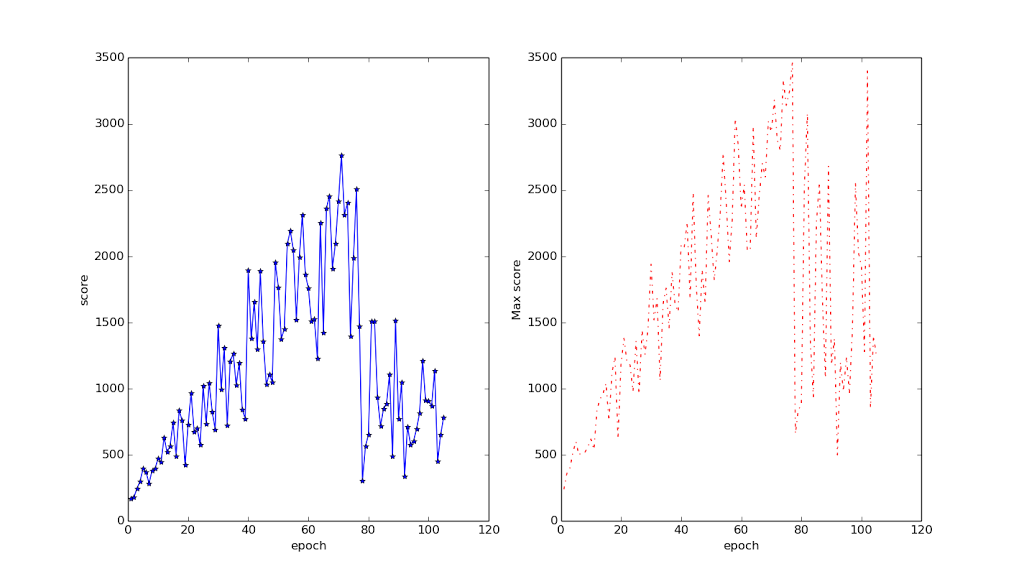
I’ve put the first 9 and a quarter hours of the game on Youtube:
It scores around 15 million points during the video, and I think over 30 million during the run (it isn’t easy to check since the points clock over every million so you have to find all the clocking overs during the run). For comparison, the highest score recorded in TwinGalaxies is around 6.6 million for someone using a real Atari, and around 10 million for someone using an emulator.
If you watch the game even for a little bit you can tell that the computer doesn’t play very well at all. It constantly misses on most of its shots. What it does super-humanly though, is kill the laser-shooting planes, and since that’s the only way you can die, it can play for a very long time.
This is a followup on the previous post. Most of the results have been replicated. Turning off Nesterov momentum, pumping RMSprop decay to 0.99 and setting the discount rate to 0.95 did the trick. The spikes in the Q-score plot that were observed with the parameters used previously that I mentioned in the last post seemed to have been caused by the momentum making the optimisation diverge, not by Q-learning itself diverging as I thought previously.
Just to be completely clear, none of this is by me: all the learning code, to which I will refer to as deep_q_rl, is by Nathan Sprague, and the algorithm is from the paper “Playing Atari with Deep Reinforcement Learning” by Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra and Martin Riedmiller that you can get from http://arxiv.org/abs/1312.5602. You can get the code from https://github.com/spragunr/deep_q_rl. I’m mainly acting as a tester.
(As I was writing this post (it has taken me almost two weeks to write), DeepMind published their updated paper on Nature (http://www.nature.com/nature/journal/v518/n7540/full/nature14236.html), and this time they’ve released their source code: https://sites.google.com/a/deepmind.com/dqn/. In this post I am mainly comparing to the original NIPS workshop paper. I will only mention the Nature paper where it seemed to clarify something about the NIPS paper)
When I write that the results are replicated, I mean that I think that the results produced by deep_q_rl are probably as good as the results that DeepMind obtained when they wrote the paper, and that all the original results seem believable considering these results. The Q-value curves still look very different, most likely because they were using a higher discount rate (*in their Nature paper they mention a discount rate of 0.99 while this code uses 0.95). Also, depending on the interpretation of the table where they list their results, DeepMind’s results might have been significantly better. It is hard to tell exactly what they mean by “average total reward” in table 1. Do they mean across the whole 200 epochs? Or testing their best model? Or testing only the final network? Or across a large swathe of the networks that were trained? I’ve taken a liberal interpretation of them to mean roughly how well does the agent score across many epochs once it looks like it has learnt. (From their Nature paper, it seems that they mix their use of episode and epoch a bit, so that the “best” seems to mean average across the testing epoch where it averaged highest, while “average” could be the average over all testing episodes)
Here are DeepMind’s average and best scores as listed in table 1:
Game
Beam rider
Breakout
Enduro
Pong
Q*Bert
Seaquest
Space invaders
DeepMind average
4092
168
470
20
1952
1705
581
DeepMind best
5184
225
661
21
4500
1740
1075
I think deep_q_rl does clearly worse than DeepMind’s code in Space Invaders, a little bit worse in Breakout, similar in Pong and Enduro, better on Q*Bert, and worse, similar or much better on Seaquest depending on your angle. I did not test on Beam rider.
I’ll just post the average and max-score curves obtained by deep_q_rl, some qualitative commentary on how the agent plays on each game, and videos showing good (biased) examples of the agent playing or montages of it learning. The graphs show average test score on the left and highest test score on the right. The x-axis is the epoch. They were obtained using a test epsilon of 0.05 (ie on each frame there is a five percent chance of performing a random action) just to be able to compare them with DeepMind’s results. I prefer watching the results of epsilon 0.01 (ie 1 percent chance of random action) since it makes it easier to tell policy problems from random errors, so I’ll be describing the behaviour of runs using those settings. Also, let me be very clear that even though I might have some negative comments on the behaviour of the agent, this is all to be taken as relative to the absolute level of blown-awayedness that I feel regarding that this works at all.
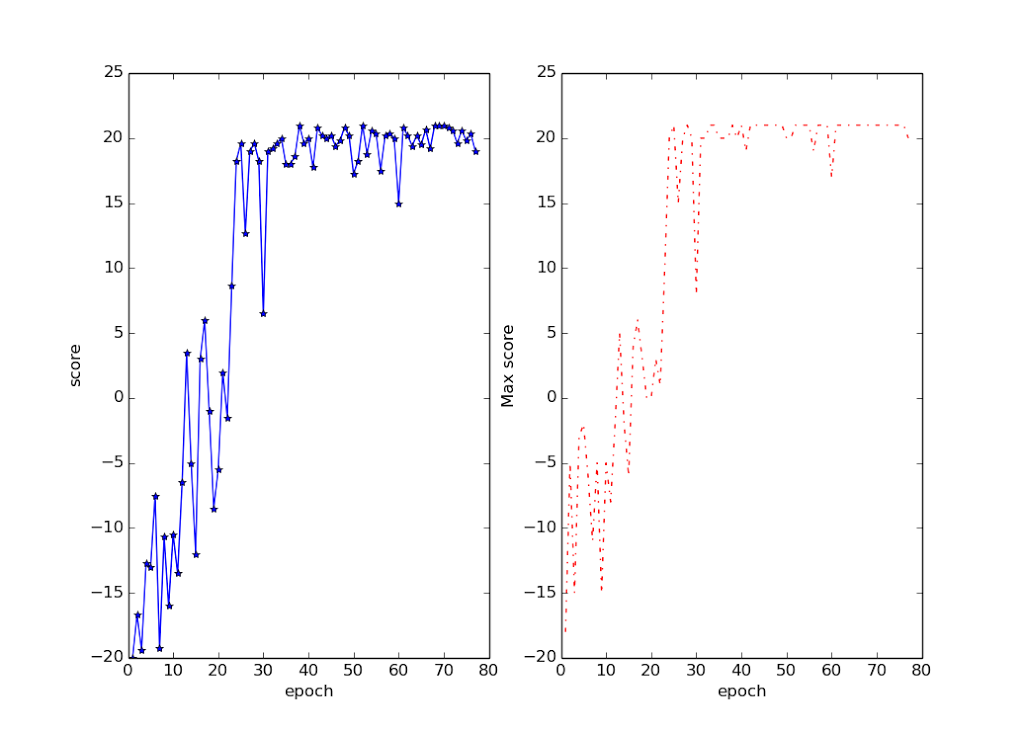
Pong
Pong is very simple and the agent learns very quickly. It plays extremely aggressively always trying to win in one hit. It mostly wins 21-0 or 21-1.
Breakout
The code learns to play breakout relatively quickly, taking about 40 epochs (1 epoch = 50000 frames) to get reasonably good at it. It plays without any seeming purpose, hitting the ball when it comes down but not aiming anywhere.
At some point it gets good enough to make a tunnel in the wall, just by repeated random hitting, and put the ball through the tunnel, scoring lots of points. It never learns to hit the ball after it comes back down through the tunnel. I think that the image looks different enough that the network does not know what to do. It mostly just sits catatonic with the paddle against the left or right wall. I have never seen it clear a level.
The difference between its high scores and its average scores once it has learnt are obtained by it being lucky, first of all by getting the ball through the tunnel quickly once it’s formed, since once the tunnel is formed its play deteriorates, and secondly by either having the ball hang around above the wall for longer or by having the paddle in the right place by accident once the ball does come back down.
Highest scored observed: 391. Obtained just as described above: random hitting leading to a hole in the middle of the wall, ball goes up and hangs around for a while, hole is in the right place for a new ball to go through it if hit by a paddle laying against the left wall.
The paper lists the average human score as 31, which I can only explain if they were using a keyboard to play the game. This game is meant to be played with a paddle, and 31 would be a pathetic score. I don’t think the scores attained by the network as better than human level.
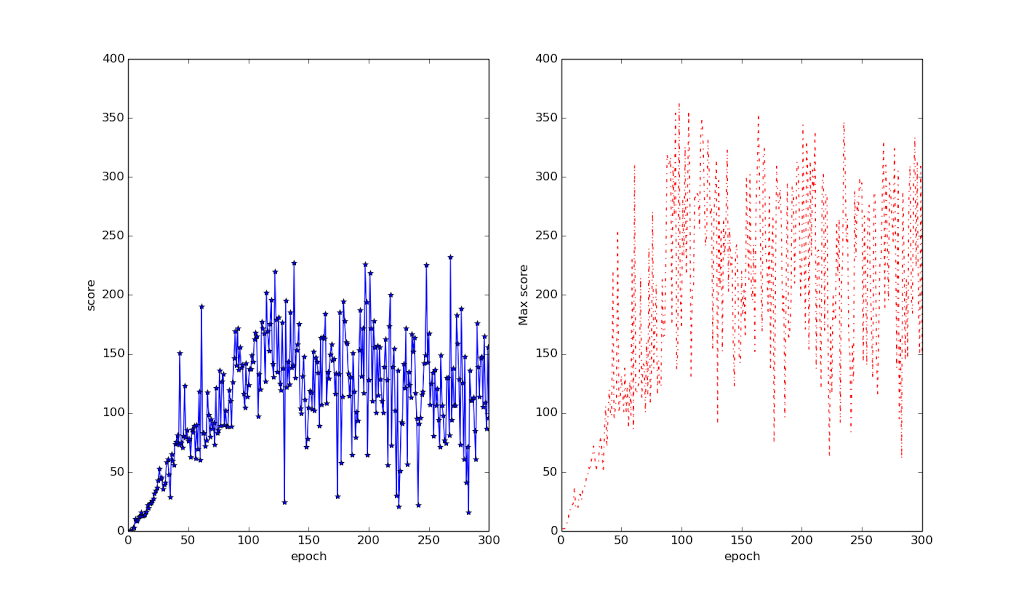
Space invaders
I expected the code to learn space invaders quite well, since it is a very simple game where the rewards come very shortly after the actions and where random thrashing at the beginning can quickly tell it what actions lead to good rewards, but it does not do very well at it, at least compared to a human.
It does learn very quickly that shooting is a good thing and within 5 epochs it gets reasonably good at shooting down invaders. It just never gets very good at evading invaders’ bullets. It does slowly improve at both tasks, and by epoch 180 or so, its play looks very similar to a novice human player, but it doesn’t keep on improving.
The huge difference between the average scores and the maximum scores for each epoch are completely due to luck. It will randomly shoot down a passing mothership which give over 300 points each. Due to the way that the image is cropped while fed to the agent, it cannot actually see the mothership though, so it being able to shoot it down is most likely just due to luck (unless it managed to find the pattern of when they appear and from which direction, something I can’t rule out).
DeepMind’s version did not do that well either, but clearly better than this one.
Highest observed score: 925 (shot two motherships)
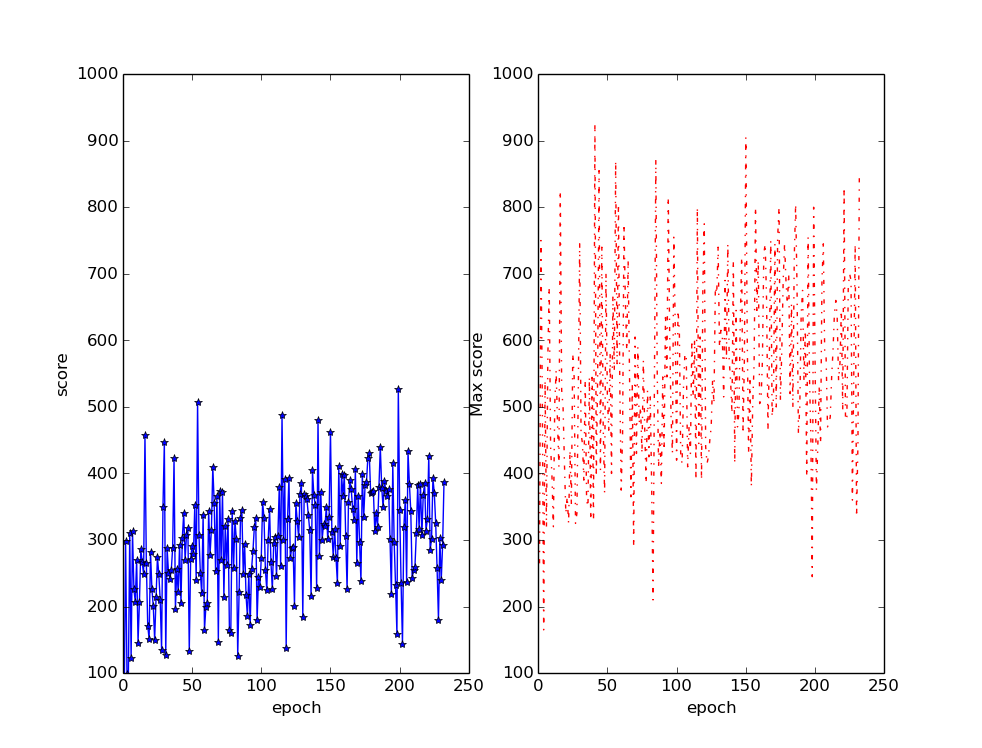
Enduro
Enduro is my favourite game to watch it play in. Its style is very non-human, combining super-human reflexes in some parts and parts where it just doesn’t know what to do.
It takes ages for it just to get any points at all in this game (almost 30 epochs). This is because points here are gotten by passing cars, and you need to keep the accelerator pressed for quite a few frames in a row to gather enough speed to pass a car. This is something that isn’t likely to happen with random joystick movements. Once it learns to do that though, it quickly gets to very high scores, learning to dodge cars at very high speed in quite different-looking environments.
It never learns what to do in the bright/glare/snow/whatever-it-is stage though, where it just waits it out or goes full tilt till it slams into the car in front of it. It is the only stage where the background is brighter than the objects to avoid, so it is understandable for it to have trouble transferring the learning from the other sections. It also learnt that you cannot gain or lose places while the flags are waving in between levels, so it doesn’t even try while they are being shown.
The high scores here track the average. Enduro takes ages to play so most of the time only one game fits in a testing epoch (10,000 frames).
When running without the 10,000 frames limit, I observed a run scoring 1080. It is part of the video below. It goes for over 7 minutes at 2x normal speed.
Seaquest
I didn’t think the code would learn to play Seaquest because, unlike in all the other games in this page, all 18 actions are available (ie up-left, up, up-right, left, neutral, right, bottom-left, bottom, bottom-right, then each again but with the button pressed), which means that picking the right one is harder. It does learn to play it, though, in a very shallow sense.
It progressively gets better at hunting down sharks and at avoiding crashing into them, all the time ignoring the divers. It gets very good at that, but it never goes up for air so it keeps dying due to lack of oxygen. Eventually, it discovers that going up for air means getting points for rescued divers. This seems to have a negative effect on its agility though and it starts crashing into everything, and its scores get hammered.
Its best runs are in that short period were it is losing its basic skills but it has learnt about surfacing. The highest score I observed was 4000. It is included in the video below.
Q*Bert
It learns to cover the first level very efficiently. The second level is a slightly different colour though, so that trips it up. It manages to learn to get some points on the second level but that seems to have a negative effect on its proficiency on the first level. I left it training for a while to see if it’d make the jump but no cigar.
Deep Mind is a company that got bought by Google at the beginning of 2014 for the usual gazillion dollars that everything seems to get bought by nowadays. They published a paper not long before that showing how they combined a deepish convolutional neural network with Q-learning to get computers to learn to play quite a few Atari games solely from the screen pixels and the score. This is something I’ve tried to do before so I thought it was very exciting news and that I should try to replicate it.
By the way, if you haven’t seen any of the demo videos showing the results, or haven’t read the paper, go have a look. The paper is “Playing Atari with Deep Reinforcement Learning” by Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra and Martin Riedmiller . Get it from http://arxiv.org/abs/1312.5602 The rest of the post will make much more sense if you have read through the paper.
A year passed and I still hadn’t attempted any replication. This was quite lucky since Nathan Sprague did, and some of the Theano code he needed to write looks beyond me. His code is here: https://github.com/spragunr/deep_q_rl (which I’ll call the Sprague code).
There are probably a few differences in the details between the implementations by Prof Sprague and Deep Mind. The ones that I noticed are the following:
The Sprague code downsamples the 160 x 210 screen to 80 x 105, and then squeezes this into an 80 x 80 input layer, while the Deep Mind version downsamples to 84 x 110 and then crops an 84 x 84 section of it for the input layer. The 80 was most likely chosen by Prof Sprague so that the downsampling would be neat (two to one), but I suspect that the 84 was chosen for the same reason ie so that the resultant image would smear a bit, making everything a bit larger.
While the Deep Mind implementation mentions that they used Rprop for the weight updating, the Sprague code implements RMSProp with Nesterov momentum.
The discount rate (gamma in Q-learning) is not mentioned in the paper. The Sprague code sets it to 0.9
I got some time to download the code and test it a bit over the new year’s break and it does brilliantly, even though not quite as brilliantly as what’s described in the paper. Deep Mind’s paper claim they got an average score of 168 on breakout and 1705 on seaquest while the Sprague code topped out at about 50 for breakout and didn’t seem to learn on seaquest. I haven’t tried it on any other games yet.
Each 100-episode run takes a bit over 24 hours on my beastly new GTX 970, so there haven’t been too many experiments yet. I did make quite a few changes to the code, but mostly to make it easier to use and other non-learning-related changes.
The few changes that I’ve made that could affect the learning are the following:
Changed it to match the Deep Mind’s paper more closely by using the crop-to-84×84 method, choosing the bottom part of the image.
Made the conversion to grayscale follow whatever it is that cv2 and pillow do that tries to match the way that humans perceive luminance which means that it pays more attention to the green component than to the blue. The original Sprague code simply averages the red, green and blue components.
The number of actions is now restricted to the number of actions provided by the hardware used for that game. For most games, that is the joystick so all 18 actions are used as by default (that is neutral, up, down, left, right, up-left, up-right, down-left, down-right, and also each one of those with the button pressed). Breakout and pong and some others were played with a paddle though, so only six actions are allowed: neutral, left, right, and each one of those with the button pressed. I am not sure if the original paper did this or not.
I’ve played around with the discount rate currently settling on 0.95
As an aside, the change to the input selection showed the sensitivity of the code to the input. I initially used pillow to do the downsampling, instead of the cv2 library as used in the original Sprague code, as pillow is easier to install. This change was enough for the program to stop learning altogether on breakout. Comparing the downsampling produced by pillow vs the downsampling produced by cv2, it seems like cv2 smears the image a bit more, making the ball quite a bit bigger than what happens with the pillow downsampling (note: this is using pillow 2.6.1. The 2.7.0 release seems to change the downsampling algorithm to be a bit more like cv2).
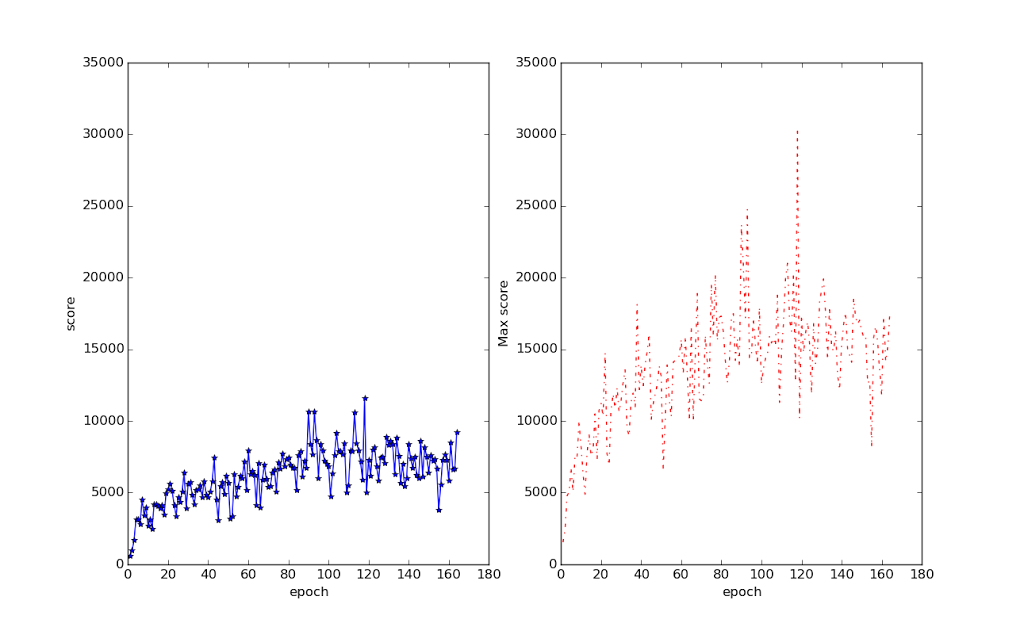
While I still haven’t seen any learning on seaquest, the program got to an average score of slightly over 100 in some of the testing epochs, while regularly averaging over 70. Here is its current masterpiece, a 331 produced after about 18 hours of training:
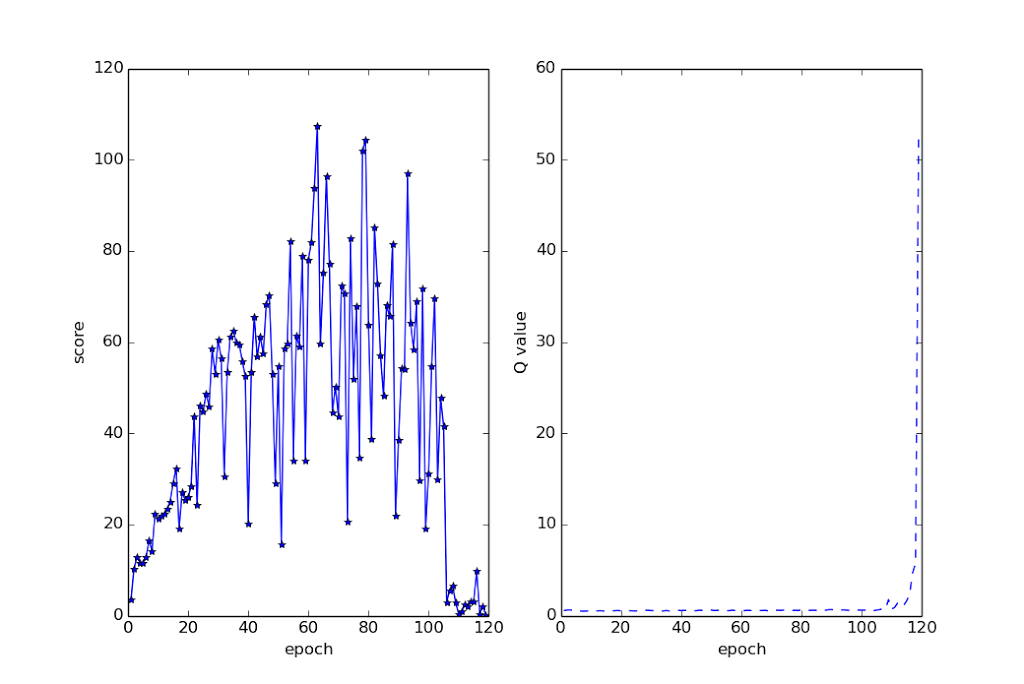
Here is the more accurate picture of its results, plotting epoch vs score, and the Q-value on a test set, similar to what’s shown on page 5 of the paper:
The score plotted for an epoch is the result of a testing round that is done after that epoch. The testing runs for 10000 frames. That’s about eight or nine games when it’s doing well. Note the collapse of the score around epoch 103 or so, with the Q-value going whacked shortly after that. That, I think, is the Q-learning diverging. If you look in the paper, their Q-value goes smoothly up. This one never does, not even before the divergence.
My fork is at https://github.com/alito/deep_q_rl . I will probably keep tweaking with it. I expect the code to learn nicely on pong, but I’m not sure on other games. Here are some ideas for it:
Try converting the cnn_q_learner to use the default Theano convolutional code which uses the NVIDIA cuDNN code. It should be a bit faster than the cuda_convnet code.
Try Rprop instead of RMSprop
Test adapting discount rates
Change the network architecture (bigger, deeper)
Change the algorithm to use more time-separated frames as inputs, rather than the last four frames.