I think DeepMind was a bit unlucky in not choosing Galaxian as one of their original set of games to train on. It’s a very popular game, much more interesting than its Space Invaders ancestor, and, more importantly, their algorithm learns great on it.
Here are the usual graphs for it: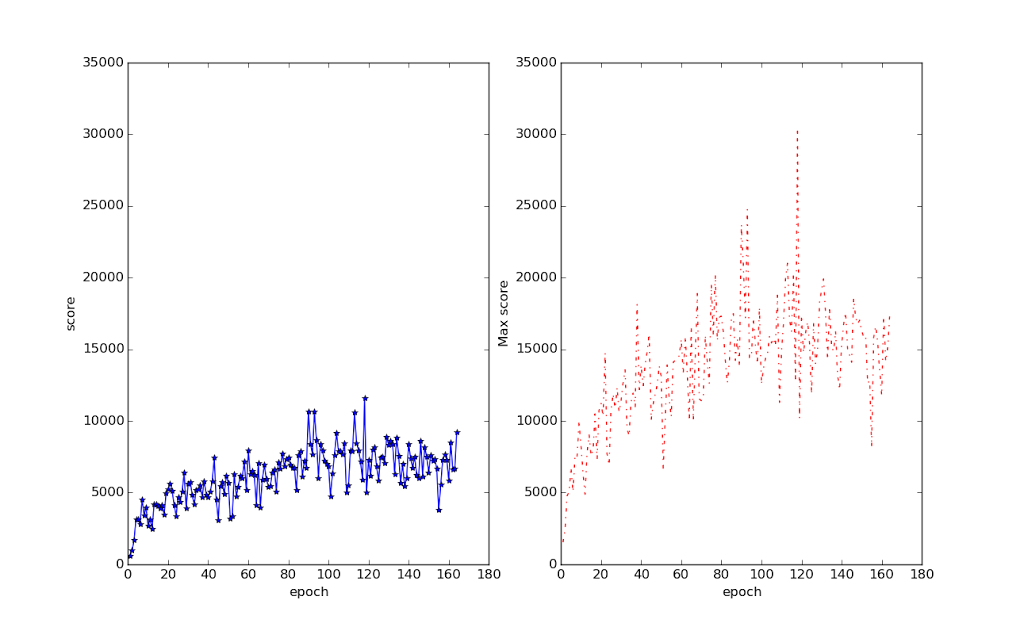
Note that, unlike in the Space Invaders case, these scores are very much human-level. Those scores in the high 20,000 range are really hard to get unless you play the game a lot. Even the 10,000 average is very respectable. It also very quickly reaches perfectly-reasonable and quite human-styled levels of play (less than 10 epochs).
I made a learning-progression video for it:
I used run_nature.py from Nathan Sprague’s code (https://github.com/spragunr/deep_q_rl). You’ll need a newish version of ALE (https://github.com/mgbellemare/Arcade-Learning-Environment) to train this since code to support Galaxian was only incorporated recently (commit c62378aece70cfb119d0d4111d15b4b830a23d6c or later).