Deep Mind is a company that got bought by Google at the beginning of 2014 for the usual gazillion dollars that everything seems to get bought by nowadays. They published a paper not long before that showing how they combined a deepish convolutional neural network with Q-learning to get computers to learn to play quite a few Atari games solely from the screen pixels and the score. This is something I’ve tried to do before so I thought it was very exciting news and that I should try to replicate it.
By the way, if you haven’t seen any of the demo videos showing the results, or haven’t read the paper, go have a look. The paper is “Playing Atari with Deep Reinforcement Learning” by Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra and Martin Riedmiller . Get it from http://arxiv.org/abs/1312.5602 The rest of the post will make much more sense if you have read through the paper.
A year passed and I still hadn’t attempted any replication. This was quite lucky since Nathan Sprague did, and some of the Theano code he needed to write looks beyond me. His code is here: https://github.com/spragunr/deep_q_rl (which I’ll call the Sprague code).
There are probably a few differences in the details between the implementations by Prof Sprague and Deep Mind. The ones that I noticed are the following:
- The Sprague code downsamples the 160 x 210 screen to 80 x 105, and then squeezes this into an 80 x 80 input layer, while the Deep Mind version downsamples to 84 x 110 and then crops an 84 x 84 section of it for the input layer. The 80 was most likely chosen by Prof Sprague so that the downsampling would be neat (two to one), but I suspect that the 84 was chosen for the same reason ie so that the resultant image would smear a bit, making everything a bit larger.
- While the Deep Mind implementation mentions that they used Rprop for the weight updating, the Sprague code implements RMSProp with Nesterov momentum.
- The discount rate (gamma in Q-learning) is not mentioned in the paper. The Sprague code sets it to 0.9
I got some time to download the code and test it a bit over the new year’s break and it does brilliantly, even though not quite as brilliantly as what’s described in the paper. Deep Mind’s paper claim they got an average score of 168 on breakout and 1705 on seaquest while the Sprague code topped out at about 50 for breakout and didn’t seem to learn on seaquest. I haven’t tried it on any other games yet.
Each 100-episode run takes a bit over 24 hours on my beastly new GTX 970, so there haven’t been too many experiments yet. I did make quite a few changes to the code, but mostly to make it easier to use and other non-learning-related changes.
The few changes that I’ve made that could affect the learning are the following:
- Changed it to match the Deep Mind’s paper more closely by using the crop-to-84×84 method, choosing the bottom part of the image.
- Made the conversion to grayscale follow whatever it is that cv2 and pillow do that tries to match the way that humans perceive luminance which means that it pays more attention to the green component than to the blue. The original Sprague code simply averages the red, green and blue components.
- The number of actions is now restricted to the number of actions provided by the hardware used for that game. For most games, that is the joystick so all 18 actions are used as by default (that is neutral, up, down, left, right, up-left, up-right, down-left, down-right, and also each one of those with the button pressed). Breakout and pong and some others were played with a paddle though, so only six actions are allowed: neutral, left, right, and each one of those with the button pressed. I am not sure if the original paper did this or not.
- I’ve played around with the discount rate currently settling on 0.95
As an aside, the change to the input selection showed the sensitivity of the code to the input. I initially used pillow to do the downsampling, instead of the cv2 library as used in the original Sprague code, as pillow is easier to install. This change was enough for the program to stop learning altogether on breakout. Comparing the downsampling produced by pillow vs the downsampling produced by cv2, it seems like cv2 smears the image a bit more, making the ball quite a bit bigger than what happens with the pillow downsampling (note: this is using pillow 2.6.1. The 2.7.0 release seems to change the downsampling algorithm to be a bit more like cv2).
Here is the more accurate picture of its results, plotting epoch vs score, and the Q-value on a test set, similar to what’s shown on page 5 of the paper:
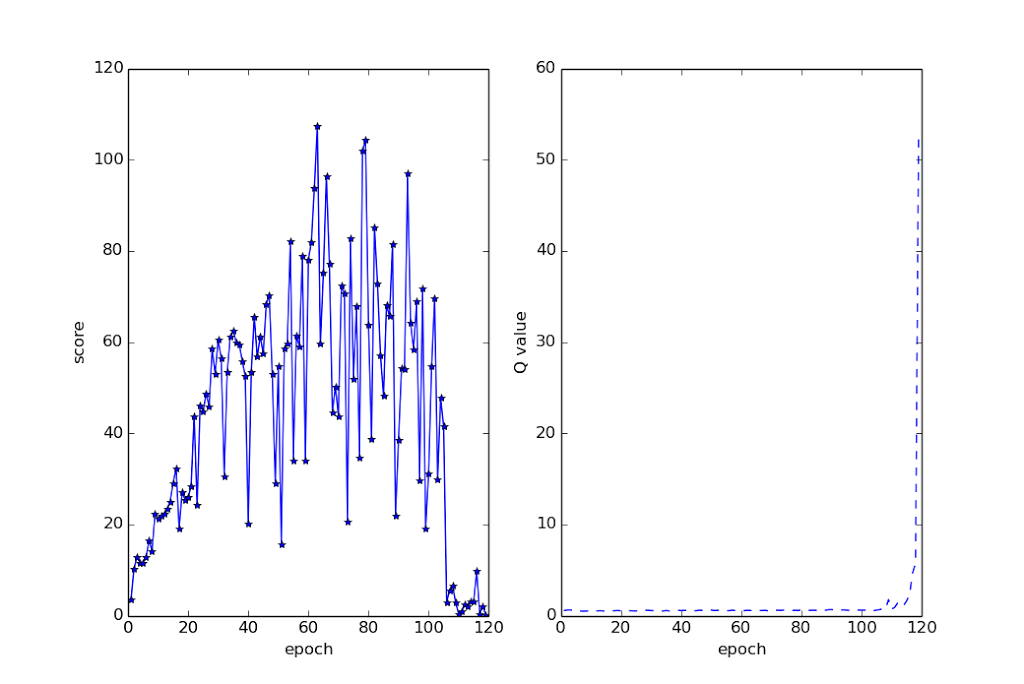
The score plotted for an epoch is the result of a testing round that is done after that epoch. The testing runs for 10000 frames. That’s about eight or nine games when it’s doing well. Note the collapse of the score around epoch 103 or so, with the Q-value going whacked shortly after that. That, I think, is the Q-learning diverging. If you look in the paper, their Q-value goes smoothly up. This one never does, not even before the divergence.
My fork is at https://github.com/alito/deep_q_rl . I will probably keep tweaking with it. I expect the code to learn nicely on pong, but I’m not sure on other games. Here are some ideas for it:
- Try converting the cnn_q_learner to use the default Theano convolutional code which uses the NVIDIA cuDNN code. It should be a bit faster than the cuda_convnet code.
- Try Rprop instead of RMSprop
- Test adapting discount rates
- Change the network architecture (bigger, deeper)
- Change the algorithm to use more time-separated frames as inputs, rather than the last four frames.
Hi,
I am not sure if my previous post appeared here.
Best,
Marek
Nope, there doesn't seem to be any other comment awaiting moderation and it doesn't seem to be stuck in the spam folder either, sorry.
Anyway, I am trying to run prof Sprague's code for Breakout but the network doesn't seem to be able to learn anything except for for the agent to stay in one corner all the time. Did you notice that?
Btw, would you mind sharing your trained parameters file on Breakout?
How many epochs did you leave it running for? (any less than 20 and you should just leave it running for longer) Has it happened on more than one restart? I have heard of this happening on a couple of occasions to other people, probably due to unlucky initialisation values, but I have never encountered it myself.
In any case, better to post to the list related to the deep_q_rl code since there's quite a few people that can help you. It's here: https://groups.google.com/forum/#!forum/deep-q-learning
I can also send you a trained network if you really want, but I suspect just rerunning your training overnight will just work. You could also try the code from my branch, since there's two very small differences with the main branch
The most I've run it for was 40 I think and it yielded exactly the same result. I guess I could use a specific seed but don't think it should be that bad though. I've modified the code slightly using a different interpolator – scipy.imresize but dont think that should be a problem.
I would appreciate it you could send me yours, I've spent a lot of time trying to debug it and would be able to hopefully debug it successfully.
I'll have a look at the list now.
This comment has been removed by the author.
Like I noted in the text of the blog, the code is very sensitive to the input. Changing the interpolator to scipy.imresize could definitely be a problem.
I'll send you a trained network through email
Ah, no, I don't have your email address. I'll post it on the deep_q_rl list.
HI, does anyone knows how many neurons and how many layers are in this network ? I couldn't find this information anywhere.
Also, what is the structure of the network ? where can I see the connectivity of the neurons inside ?
I'm very interesting about that,
Thanks.